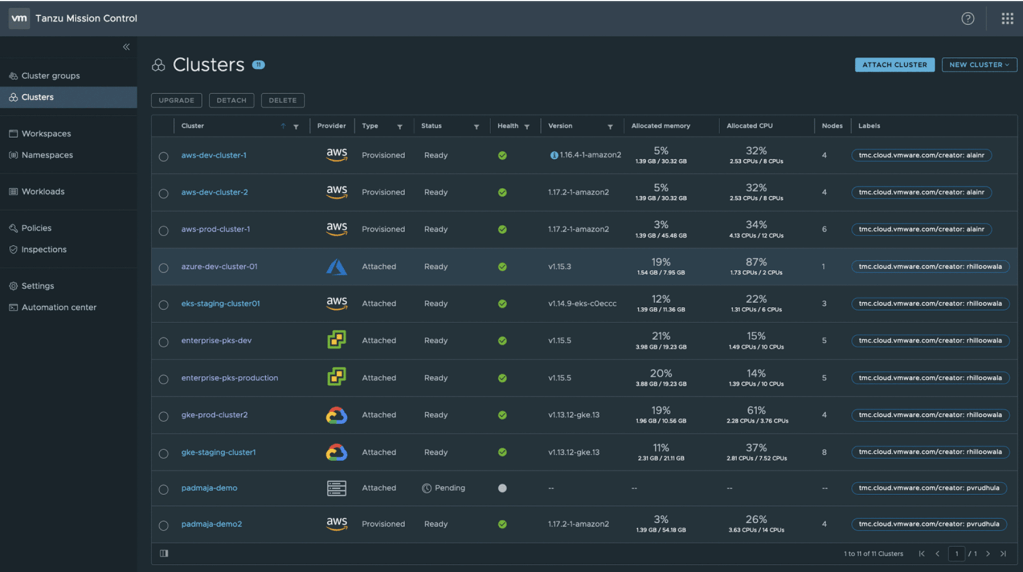
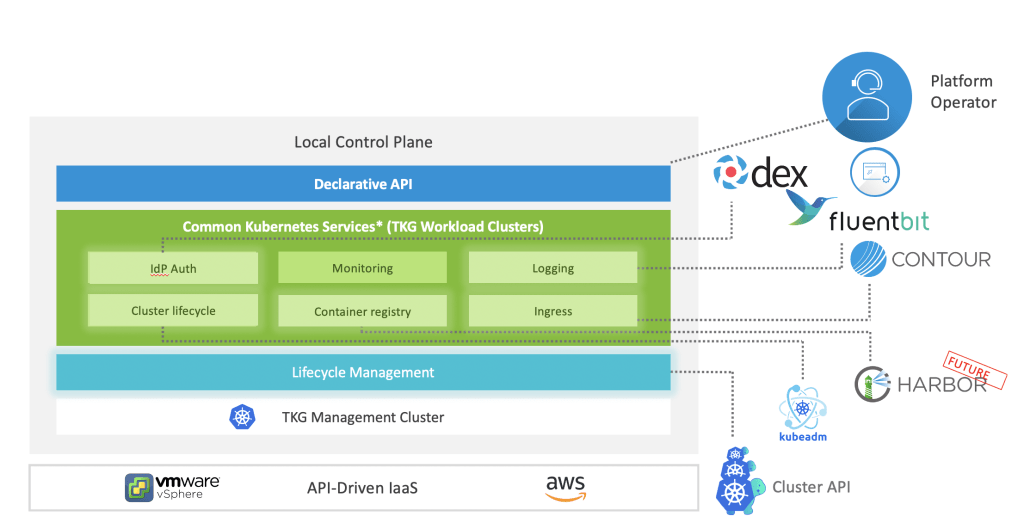
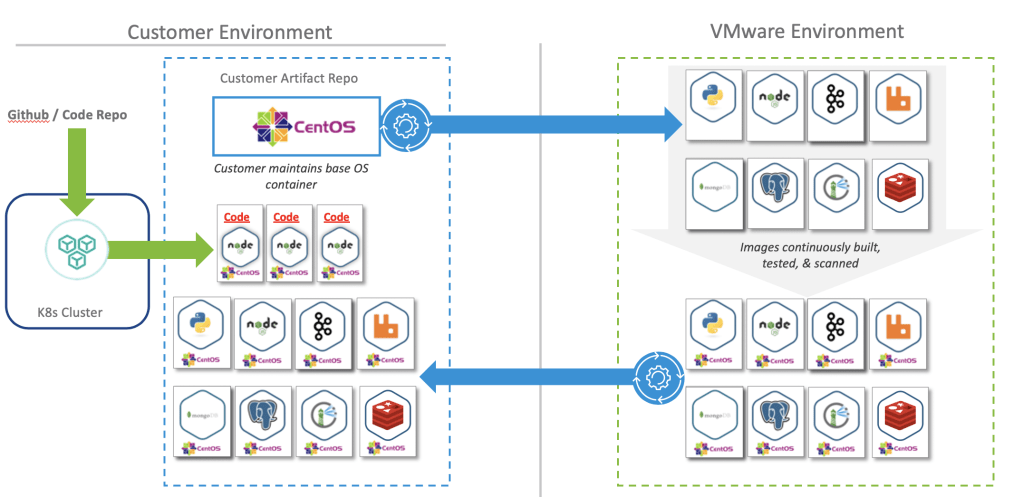
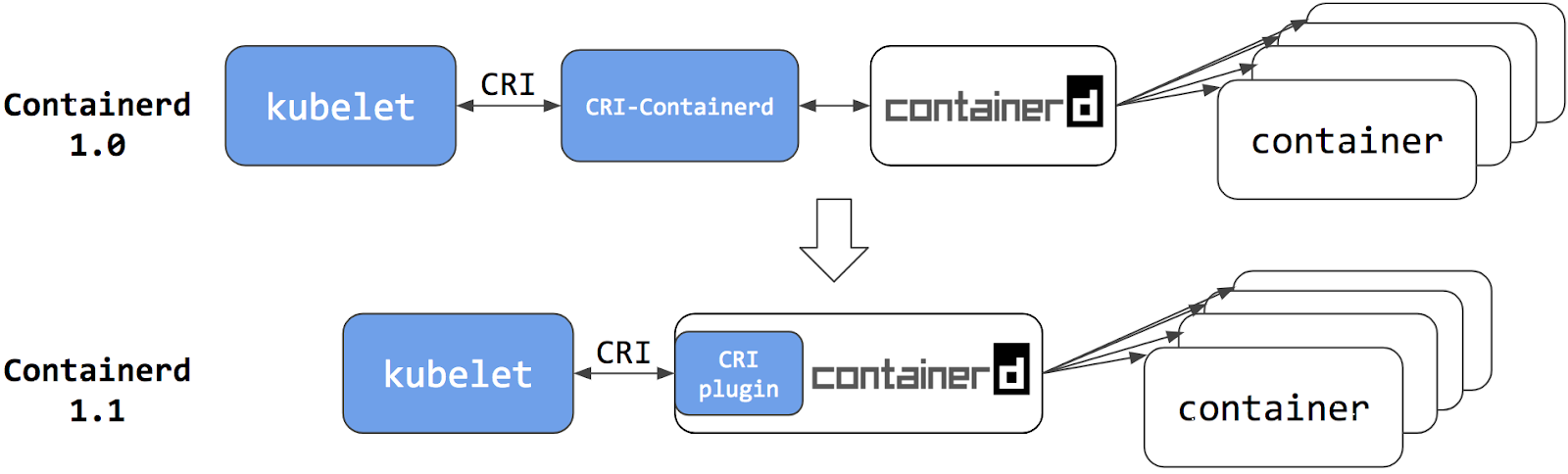
In this blog, I will cover a quick introduction of WaveFront/Tanzu Observability (TO) and a couple of use cases and real challenges which can be solved using this:
What is WaveFront Tanzu Observability (TO)?
Monitor full-stack applications to cloud infrastructures with metrics, traces, span logs, and analytics. It provides extra features beyond any other APM tool
https://tanzu.vmware.com/observability
WaveFront is an APM tool and provides additional features beyond APM for monitoring your modern cloud native microservice applications, infrastructure, VMs, K8s clusters, and alerting in real-time, across multi-cloud, Kubernetes clusters, and on-prem at any scale. Traditional tools and environments make it challenging and time consuming to correlate data and get visibility thru a single plane of the glass or dashboard needed to resolve incidents in seconds in critical production environment. It’s a unified solution with analytics (including AI) that ingests visualizes, and analyses metrics, traces, histograms and span logs. So you can resolve incidents faster across cloud applications.
Features:
- It can work with existing monitoring solutions open-sources like Prometheus, Grafana, Graphite
- It has integration almost all popular monitoring solutions on VM and containers, SpringBoot, Kubernetes, messaging platforms, RabbiMQ, Databases etc.
- It monitors containers and VMs stats
- It captures all microservices APIs traces, usage and performance with topology view by it’s powerful service discovery features
- It maintains versions of charts and dashboards
- Currently it stores and archive old monitoring data for analytics purposes
High Level Technical Architecture

WaveFront use cases:
- Multicloud visibility (mostly data center, moving to public cloud)
- Application monitoring (+ tooling for Dev and Ops visibility)
- Service performance and reliability optimization (assess-verify)
- Observability and diagnostics of multi-cloud and on-prem K8s clusters
- Business service performance & KPIs
- App metrics: from New Relic, Prometheus and Splunk
- Multicloud metrics: from vSphere, AWS, Kubernetes
- All data center metrics: from compute, network, storage
- Reliability and high availability operations
- App and Infrastructure monitoring , analytics dashboards
- Auto alerting mechanism for any production bug or high usage of infrastructure (CPU, RAM, Storage)
- Instrument and monitor your Spring Boot application in Kubernetes
- Other Tanzu products monitoring
- System-wide monitoring and incident response – cut MTTR
- Shared visibility across biz, app, cloud/infra, device metrics
- IoT optimization with automated analytics on device metrics
- Microservices monitoring and troubleshooting
- Accelerated anomaly detection
- Visibility across Kubernetes at all levels
- Solving cardinality limitations of graphite
- Easy adoption across hundreds of developers
- System-wide monitoring and incident response – cut MTTR
- Shared visibility across biz, app, cloud/infra, device metrics
- IoT optimization with automated analytics on device metrics
- AWS infrastructure visibility (cost and performance)
- Kubernetes monitoring
- Visualizing serverless workloads
- Solving Day 2 Operations for production issues and DevOps/DevSecOps
- Finding hidden problems early and increase SLA for service ticket resolution
- Application and microservices API monitoring
- Performance analytics
- Monitoring CI/CD like Jenkins Environment with Wavefront
Live WaveFront Dashboard

References
- Doc: https://docs.wavefront.com/
- Integrations: https://www.wavefront.com/integrations/